A càrrec de Ghazaleh Keshavarzkalhori, Cristina Perez-Sola, Guillermo Navarro-Arribas, Jordi Herrera-Joancomartí i Habib Yajam
En un món on la privadesa de les dades és més important que mai, l’aprenentatge federat ha emergit com una manera potent d’entrenar models d’aprenentatge automàtic de manera col·laborativa, sense necessitat de compartir dades en brut. Introduït originalment per Google, aquest enfocament permet als propietaris de dades entrenar models localment amb les seves dades i després enviar aquests models entrenats (no les dades) de tornada a un servidor central on s’agreguen en un model global.
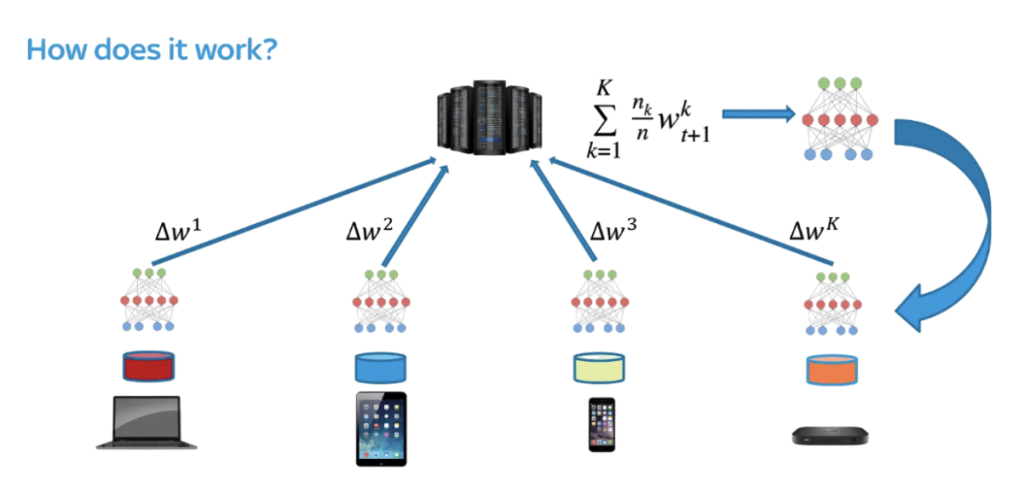
És una solució elegant, fins que comences a mirar els reptes de privadesa i seguretat que hi ha sota el capó.
Per què l’aprenentatge federat no és suficient per a la privadesa?
L’aprenentatge federat va ser inicialment elogiat pels seus beneficis de privadesa. Per exemple, Google el va utilitzar per entrenar el teclat de Gboard mantenint els textos dels usuaris privats. Pensem-hi intuïtivament. Si tots enviéssim els nostres models a un servidor per combinar-los, algú podria intentar escriure frases a mig acabar i veure com respon el nostre model. Això podria donar-los informació sobre com escrivim normalment, cosa que és un gran problema de privadesa.
Suposant que el model està ben entrenat, la sortida del model seria el que probablement diré. Això vol dir que qualsevol persona amb un diccionari predefinit d’oracions podria inferir com podria escriure o completar una oració.
En termes més generals i tècnics, es poden aplicar tres atacs diferents que s’expliquen a continuació a un aprenentatge federat simple:
- Els atacs d’inferència de pertinença poden detectar si s’han utilitzat dades d’un usuari específic per entrenar el model.
- Els atacs d’inferència de propietats poden endevinar detalls ocults com la ubicació geogràfica o l’entorn del dispositiu.
- Els atacs de reconstrucció poden fins i tot intentar recrear les dades originals.
Tot això fa referència a la privadesa de la formació, analitzant quanta informació es pot filtrar quan la formació es distribueix entre múltiples propietaris de dades, en lloc d’un servidor central. Tanmateix, amb la distribució sempre sorgeix la qüestió de la confiança. Quant podem confiar en la formació si no la fa el nostre dispositiu i un grup de propietaris de dades?
Malauradament, la resposta és no: no podem confiar plenament en el procés.
En l’entorn d’aprenentatge federat, la confiança es defineix en dos conceptes diferents. Pensem en un escenari empresarial on diversos competidors, empreses que proporcionen detectors d’anomalies per a xarxes, es reuneixen per entrenar un detector general conjuntament. Aquest escenari té sentit perquè la majoria de les dades de xarxa són privades per a les empreses i es consideren confidencials i no es comparteixen fàcilment, però la informació d’una xarxa simple no és suficient per detectar anomalies que es produeixen en diferents xarxes, de manera que la generalització del model és imprescindible.
En el nostre escenari, podem entendre fàcilment els riscos de seguretat imposats per l’aprenentatge federat fent les dues preguntes següents.
- Podem confiar que altres empreses no generarien dades falses per espatllar el model i avançar-se als seus competidors?
- Podem confiar que el servidor que agrupa tots els nostres models calcula correctament el model final? Podem confiar que els nostres models reben un tracte just al servidor?
La primera pregunta es coneix com a enverinament i la segona com a comportament injust del servidor.
Presentació de Federify: un nou enfocament
Per abordar aquests problemes, proposem Federify, un esquema d’aprenentatge federat verificable que combina zkSNARKs, blockchain i xifratge homomòrfic. També hi ha disponible una implementació de prova de concepte de Federify a GitHub: FederatedNaiveBayesZKP.
Vegem com afrontem cadascun dels problemes.
Servidor central injust →
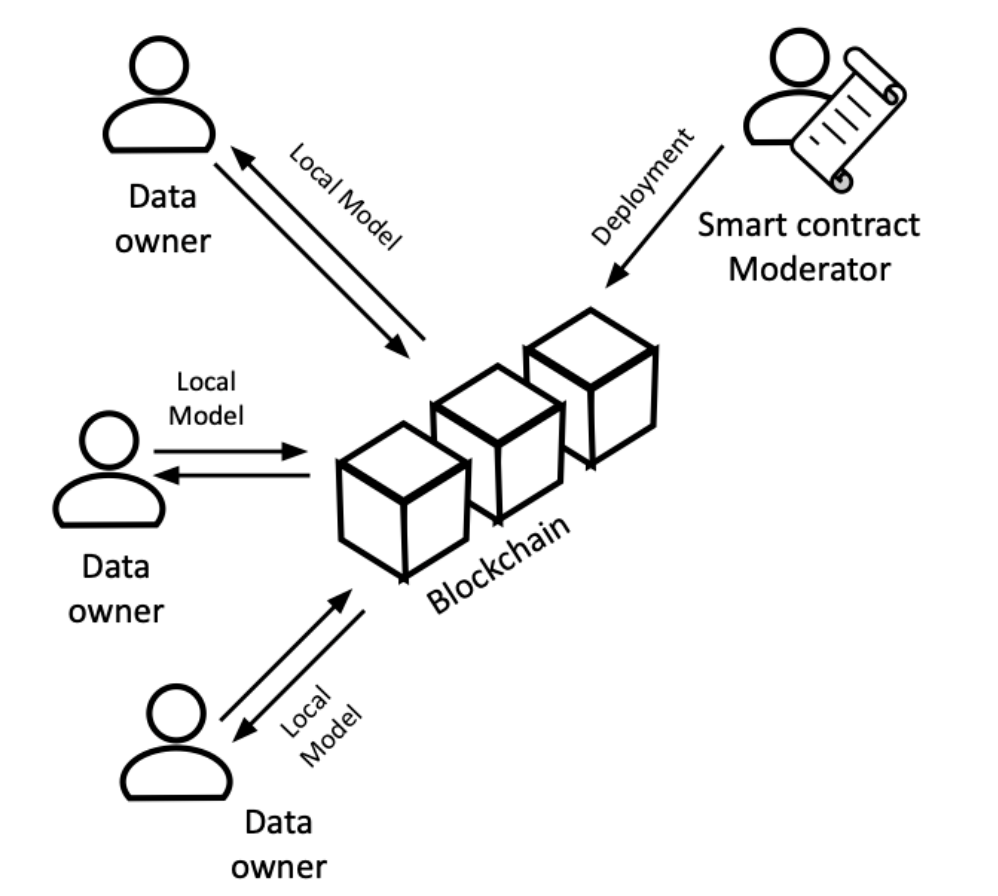
En lloc de confiar en un servidor tradicional per agrupar els nostres models, podem utilitzar blockchain i contractes intel·ligents per a una millor transparència. Els contractes intel·ligents són programes autoexecutables a la blockchain. La seva transparència i automatització permeten l’agregació verificable de models, eliminant la necessitat de confiar en un servidor central. D’aquesta manera, el càlcul del model global es pot fer de manera sense confiança.
Propietaris de dades no fiables →
Les proves de coneixement zero són proves matemàtiques probabilístiques que proven una afirmació sense revelar informació addicional sobre ella. Sembla complicat, oi?
Si us interessa el ZKP i més concretament el zkSNARK, us animo a començar el vostre viatge aprenent sobre ells aquí.
Per a aquesta publicació, assumirem que els ZKP són conjunts d’eines que, quan es passen càlculs arbitraris i algunes entrades, poden demostrar que la sortida d’aquest càlcul amb les entrades especificades és un cert valor. Bàsicament, vincula el càlcul a la seva sortida. A més d’aquesta vinculació, també pot ocultar entrades específiques al càlcul, proporcionant-nos privadesa.
In Federify, we handle the problem of untrusted data owners with the help of zkSNARKs. Each data owner trains their model on their local data and generate proof for the training sending the model and the proof to the smart contract. The smart contract will only join any local model with the global one if it’s able to verify the correctness of the model training.
Fuga d’informació de dades locals a través de models →
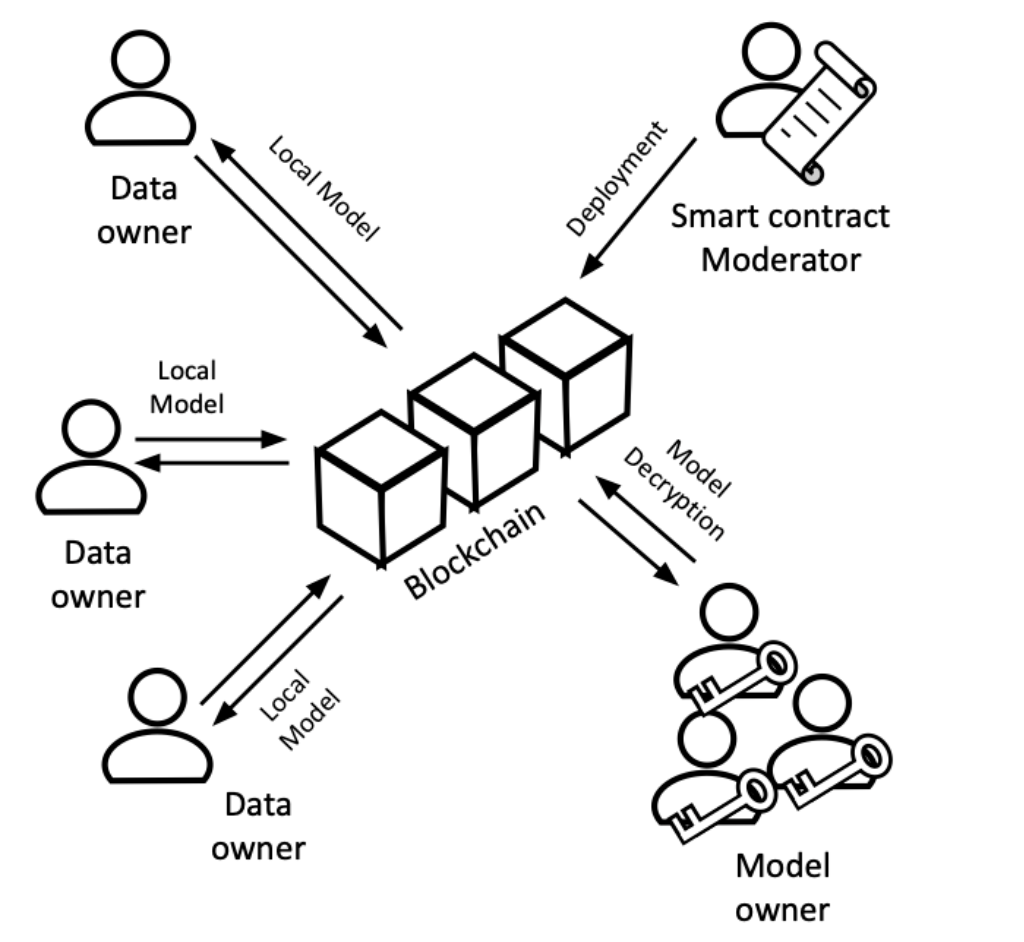
Aquest problema sorgeix de compartir públicament els nostres models locals en text sense format. Tornem a l’atac intuïtiu que vam pensar al principi. Si algú de la cadena de blocs pot veure el model que estic enviant al contracte intel·ligent, qualsevol d’ells pot utilitzar les seves entrades creades al meu model i extreure informació. Per ocultar els nostres models, podem ocultar-los fàcilment. Això es pot fer de diverses maneres, però la majoria requereixen mostrar els models abans de fer-hi cap càlcul. Com que els càlculs els fa el contracte intel·ligent i públicament això indica que no s’amaguen en absolut. Per solucionar aquest problema, amaguem els nostres models mitjançant xifratge homomòrfic. Amb el xifratge homomòrfic, les dades es poden processar sense desxifrar-les. Federify utilitza una versió multipartida d’això, és a dir, cap participant pot desxifrar els models; han de col·laborar per desbloquejar qualsevol informació.
En conclusió, Federify gestiona els riscos de seguretat i privadesa en una estructura d’aprenentatge federada de la manera següent:
- Ús de contractes intel·ligents amb càlculs transparents per gestionar servidors injustos.
- Ús de càlculs multipartits homomòrfics per ocultar els models i preservar la privadesa.
- Ús de zkSNARKs per provar càlculs realitzats localment i eliminar la confiança de l’entrenament.
Per a més detalls tècnics sobre aquest esquema, llegiu el nostre article:
Federify: A Verifiable Federated Learning Scheme Based on zkSNARKs and Blockchain
15 comments on “Federify: Fer que l’aprenentatge federat sigui verificable i segur”